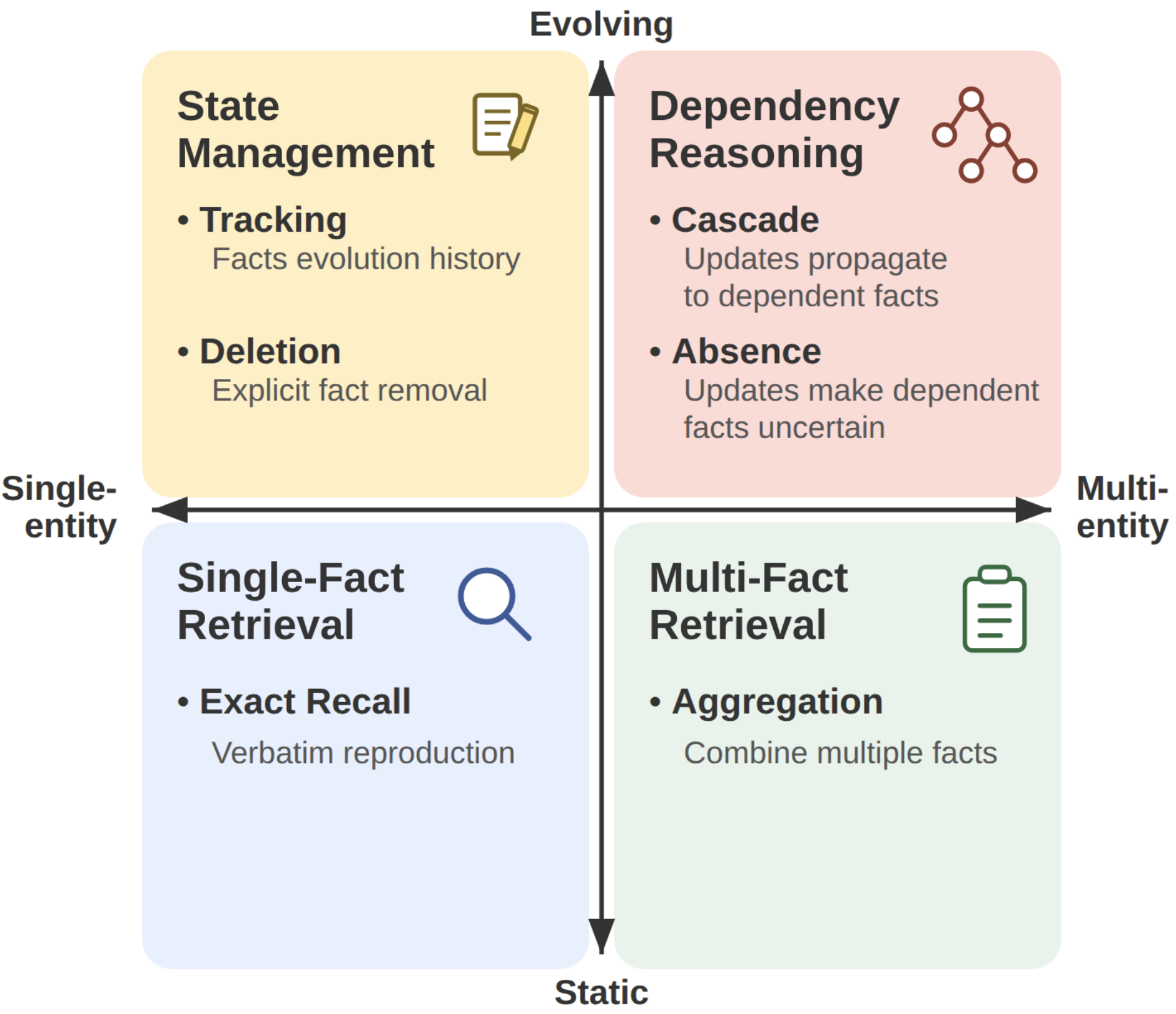
MEME Multi-Entity & Evolving Memory Evaluation

MEME defines six memory tasks spanning the full multi-entity × evolving space, including Cascade, Absence, and Deletion: three tasks that no prior benchmark scores.
Across 100 controlled episodes and six memory systems, all systems collapse on dependency reasoning under the default configuration (Cascade: 3%, Absence: 1% average accuracy), revealing that closure currently depends on configurations that are not practical at scale.
Overall result Per-task accuracy across six memory systems
| System | ER | Agg | Tr | Del | Cas | Abs | Overall | Cost $/ep | |
|---|---|---|---|---|---|---|---|---|---|
| Ingest | Inference | ||||||||
| Raw retrieval | |||||||||
| BM25 | 1.00 | 0.05 | 0.16 | 0.27 | 0.02 | 0.00 | 0.25 | — | $0.04 |
| text-emb-3-small | 0.96 | 0.33 | 0.46 | 0.17 | 0.04 | 0.00 | 0.33 | — | $0.03 |
| LLM-processed memory | |||||||||
| Mem0 | 0.67 | 0.35 | 0.43 | 0.21 | 0.03 | 0.00 | 0.28 | $0.10 | $0.01 |
| Graphiti | 0.03 | 0.01 | 0.04 | 0.09 | 0.02 | 0.01 | 0.03 | $0.55 | $0.00 |
| File-based agents | |||||||||
| MD-flat | 0.94 | 0.45 | 0.77 | 0.25 | 0.06 | 0.05 | 0.42 | $0.04 | $0.01 |
| Karpathy Wiki | 0.11 | 0.18 | 0.27 | 0.03 | 0.01 | 0.02 | 0.10 | $1.17 | $0.22 |
| Internal-LLM swap (20-ep subset) | |||||||||
| MD-flat × Opus 4.7 claude-opus-4-7 · 20 ep | 0.60 | 0.80 | 0.20 | 0.80 | 0.32 | 0.59 | 0.55 | $3.87 | $0.66 |
| Average (six main systems) | 0.62 | 0.23 | 0.35 | 0.17 | 0.03 | 0.01 | 0.24 | — | — |
Walkthrough
Episode sw_033 — software project
Result grid (6 tasks × 7 systems, after-questions)
| BM25 | text-emb-3-small | Graphiti | Karpathy Wiki | MD-flat | Mem0 | MD-flat × Opus 4.7 claude-opus-4-7 | |
|---|---|---|---|---|---|---|---|
| ER | |||||||
| Agg | |||||||
| Tr | |||||||
| Del | |||||||
| Cas | |||||||
| Abs | |||||||
| Total | 2/6 | 3/6 | 0/6 | 1/6 | 2/6 | 2/6 | 3/6 |
Click a cell to inspect the agent's actual answer for that task–system pair.
Inspect a system
memory size gold-fact %
filler session evidence session ▲probe (evaluation event)